


90% Cheaper OpenAI Embeddings, Riffusion & Custom Diffusion
and CRW RIDE is now the Latent Garage!

Hey, folks! First, a couple of small announcements.
So, CRW RIDE is now the Latent Garage.
Also, I’ve enabled Chat for this substack (available via the Substack app). If you’re looking to build some AI stuff and have some queries, feel free to ask via Chat.
Just 3 topics for today:
New embeddings model by OpenAI
Riffusion - Stable Diffusion for Music
Custom Diffusion
🎅Cost of OpenAI Embeddings API drops by >90%
First of all, what are embeddings? why do they matter?
I won’t go into too much technical detail but they basically measure the relatedness of text strings.
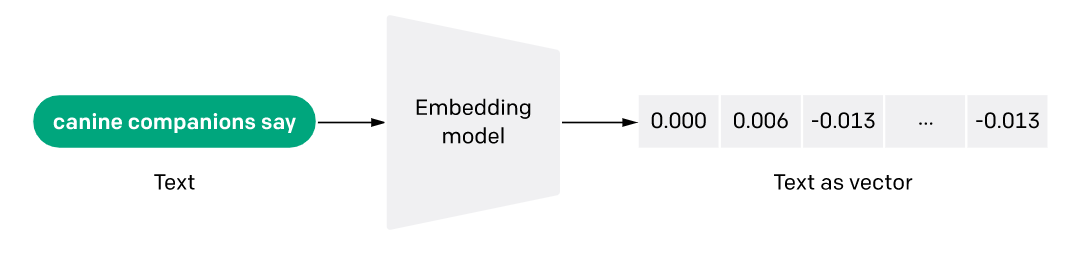
Each text string is represented as a bunch of numbers (i.e a vector). Similar texts will have similar vectors. that’s all you need to know.
So, embeddings can be used for all kinds of applications where user gives an input and wants related output. You are surrounded by these applications.
Search engines, recommendation systems, data visualization, clustering, question answering etc. The big news is that you can make all of these and it’ll cost you >90% less than before!
Not just low cost, there’s a bunch of other upgrades too:
Better & Simpler: it outperforms prior OpenAI models on most benchmark tasks and now there’s a single model for both search and similarity tasks across both text and code.
Longer context: The context length of the new model is increased by 4x. It can now embed up to 8,191 tokens (roughly ~10 pages) vs. 2,046 previously, making it more convenient to work with long documents. This is a super big deal.
10x more cost-effective: $0.0004 / 1k tokens (or roughly ~3,000 pages per US dollar). The new model achieves better or similar performance as the old Davinci models at a 99.8% lower price.
Smaller embedding size. The new embeddings have only 1536 dimensions, one-eighth the size of
davinci-001embeddings, making the new embeddings more cost effective in working with vector databases.
Cheaper, Easier, Better, Faster → Stronger 💪😂
A lot of niche search engines are gonna pop up in the coming months.
Would anyone of you like a tutorial on how to build these search engines? I am working on some semantic search engine projects. let me know. You can get started using OpenAI’s embeddings documentation and cookbook.
If you could just make a wish for one search engine, what would it be? 👇

🎵What is Riffusion?
Riffusion is a new model for generating music from prompts. Just like all the text2img models like DALL-E, Stable Diffusion etc.
Moreover, it’s just finetuned on the Stable Diffusion model! But how’s that possible?! Stable Diffusion is a model for generating images from text and it’s trained on a text-image dataset. So, Riffusion would need to be trained on a text-audio dataset to generate audio outputs, right?
That’s where things get interesting! You might already know that we can visualize the frequencies of any sound clip using a spectrogram. example: I just made this spectrogram from an audio clip. Any guesses for what the audio was?👇😛
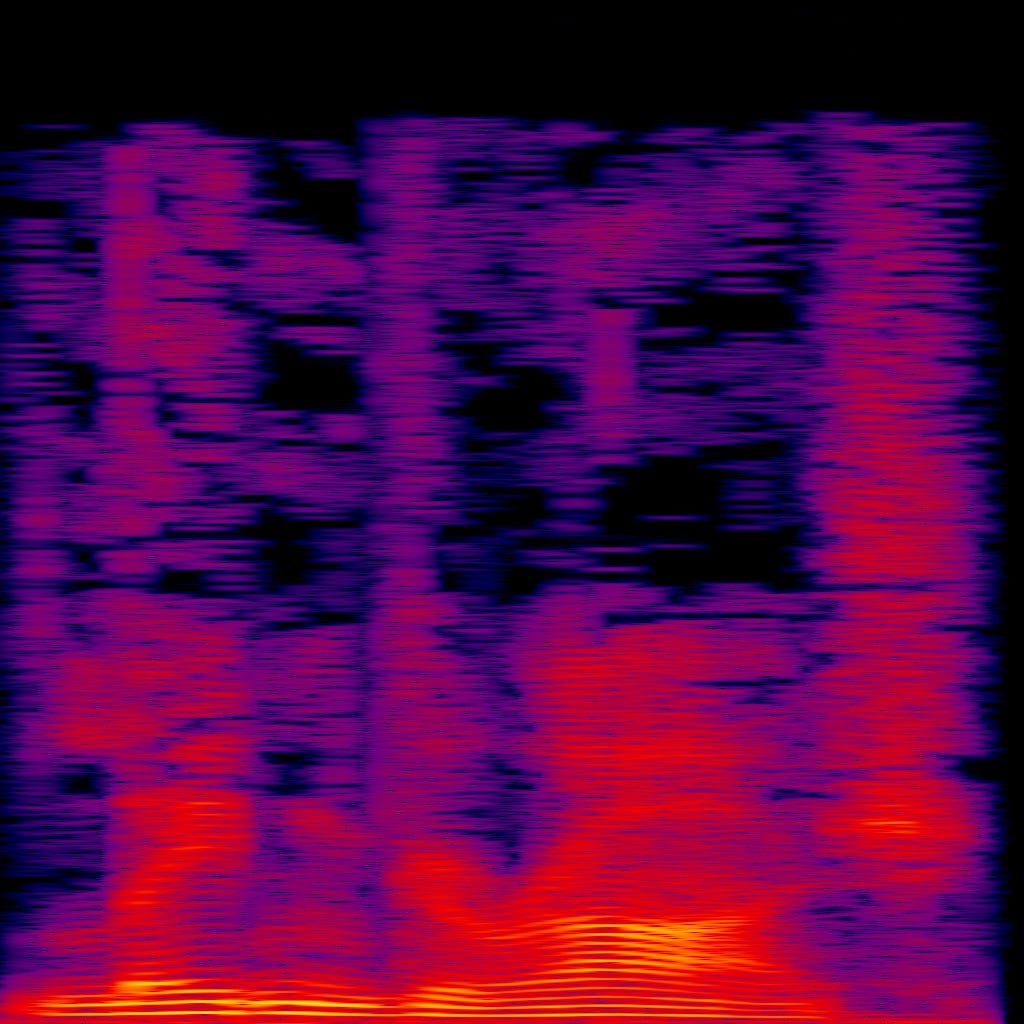
The x-axis represents time, and the y-axis represents frequency. The color of each pixel gives the amplitude of the audio at that frequency and time.

So, the audio can be converted into a spectrogram using a method called STFT (Short-time Fourier transform). The good thing is that we can get back the audio from a spectrogram as STFT works both ways!
Hence, Riffusion is just fine-tuned on images of spectrograms paired with text. So when you enter a prompt, it’ll generate spectrogram and then do audio processing to get the audio clip.
Basically, it’s a text2img model (img = spectrogram) and so you can do all the same advanced stuff which you do with stable diffusion like img2img, negative prompting etc.
You can read more here. Try out the demo here.
Want to go more in-depth? Check out this youtube tutorial.
(The generated audio isn’t really impressive. will get a lot better by Q1-Q2 2023)
🧙♂️Custom Diffusion
If you thought Dreambooth (all those AI avatar generators use it) was amazing then Custom Diffusion is next level witchcraft.
But not going into details of this one for now, I suspect that this’ll get much better in Jan, will talk then. For now, check out the demo.

That’s all.
Going forward I’ll post mainly some essays/thought pieces and also more actionable stuff - guides, tutorials on how to build stuff using AI. Weekly compilation of tutorials, perhaps?
Keeping up with all the news and compiling is a PITA so I am not sure about that. Anyways, there are others who’re doing the news compilation thing better. Even though I had a system in place for doing that, it was taking time away which I could spend building stuff.
Like think about it, in the past 3 issues; how many of you actually took some action based on the stuff I compiled! Right? It’s just too much info.
Anyways, if possible do let me know by replying here or substack chat or twitter - what type of stuff you’re looking for, which you don’t find anywhere.
Thanks a lot! Till next time 🙋♂️.
