


Curiosity Phase of Generative AI, Incumbent vs New Pro Users & more
also Microsoft has entered the chat, make AI-generated music & unlimited product photos, a prompt diagramming tool, tech stack for ML founders ...

Welcome! CRW RIDE (🔊curve-ride) is your navigator to the world of Generative AI. There’s so much happening out there; I make sense of the chaos 🧙♂️.
Whether you’re an Artist, Engineer, Founder, Investor, Content Creator or an ML Enthusiast- there’s something for everyone! The latest Research Papers, Tutorials, Open-source projects, Prompt tips, Industry Stats, Insights, Art Inspiration,Memes. Focussing on insights over news.
Alright, let’s begin this week’s ride!
Btw, the 1st issue went out to ~10 subs. Now we’re at ~80 subs! Thanks everyone!
💡PRO TIP: Click on the title above and read this in your browser as these long emails get cut off in mail apps. Also, there’s a Substack mobile app.
🍵 Appetizer
🛠 Your ML Tech Stack: Building in the Generative AI space? Bookmark this :)

💰 Stability.ai raised $101M. Their model training bill? $50M!
One crucial detail about them. It might seem like Stability.ai is the inventor of Stable Diffusion, it’s not. Researchers at RunwayML, LMU Munich released prior work. Stability.ai provided compute to researchers to retrain or something like that. As it usually happens, most folks won’t ever know these details. You do 😎. (my source)

Basically, it’s a collaborative effort. There’s no single inventor. This is what a true open-source, hacker culture looks like! Like I remember using some generative models (VQGAN+CLIP etc) in August of last year, the makers of those models now work at Midjourney, StabilityAI etc. Also, there are many other models too.


btw, I didn’t publish anything last week. More on that later.
🍱 Main Course
(TIL: there’s a bento box emoji)
Incumbent vs New Pro Users
Before talking about Pro users, let’s understand the Curiosity Phase of a new technology.
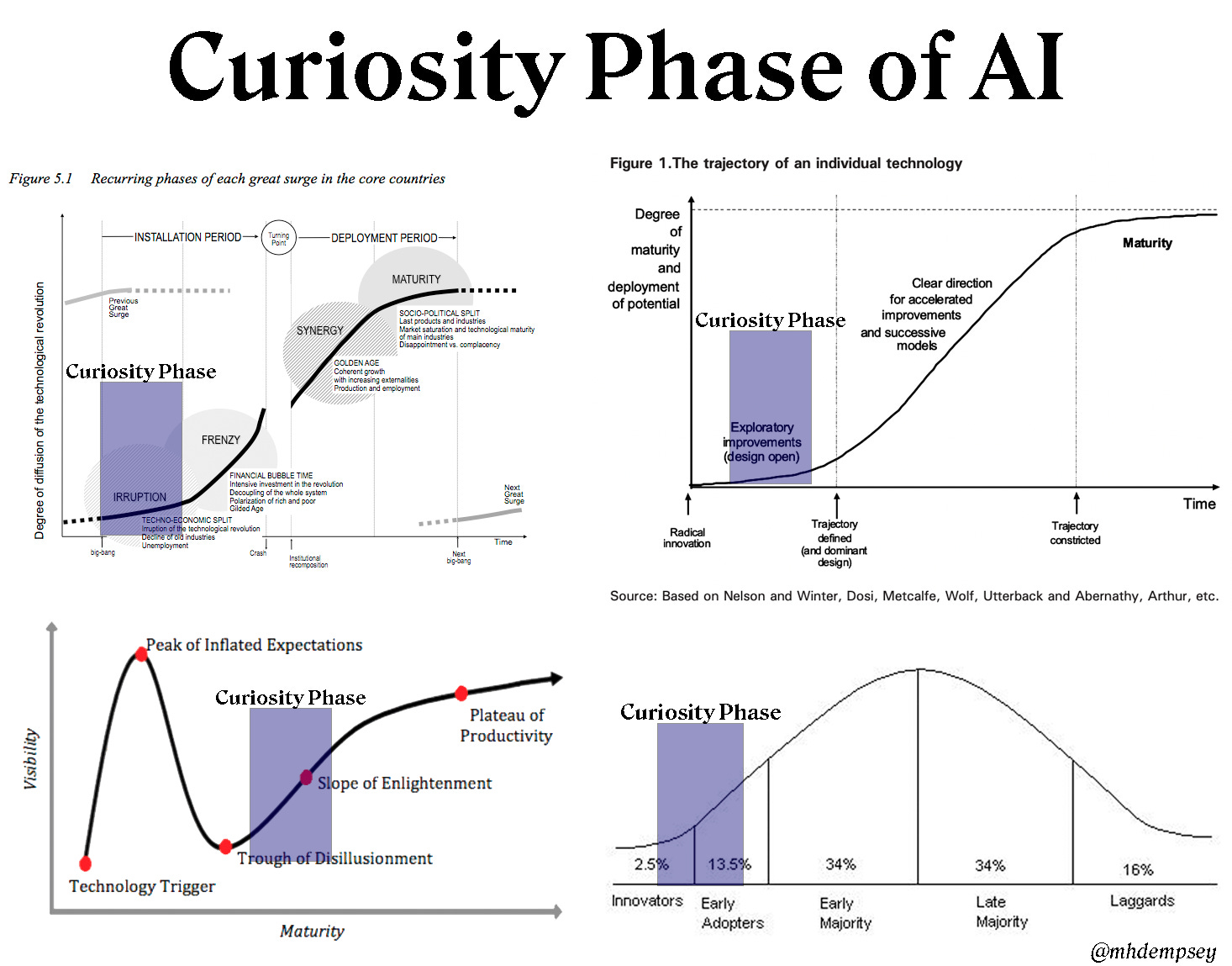
TLDR: new tech becomes widely available → wide base of users can try it out now → but value prop + core product primitives not obvious → tons of opportunities, room for experiments → lots of hype around use cases & value creation.
i.e dangerous time for those building long-lasting products. 👇


If you’re on twitter these days you have likely seen a wave of videos that utilize things like Stable Diffusion for fun and novel product concepts/demos …This reminds me a lot of prior concept-heavy phases of AR and VR … fun the first time you watched them and lost luster over the subsequent viewings as we all litigated how much we really would use a given use-case…
- Michael Dempsey
Thus, it’s important to understand your customer profile. For AI-first companies, targeting a specific type (Incumbent or New) of “professional user” is one way to think about this.
The Incumbent Professional users will see the existing “professional” workflows upended by AI due to:
An efficiency increase
A quality of work increase
A collapse of features from disparate products into a single product
A previously impossible feature that is important enough to expand budget or move budget towards the AI-first product
The New Professional users will become paying customers and benefit from:
The democratization of a skillset leading to a specific job of their industry’s stack being made obsolete from AI
AI enabling a new worker-type, leading to the worker doing a job despite having different qualifications from the prior person who did the job without AI
A lowered barrier of entry to a part of the industry that brings consumers or prosumers to professional level or removes the middleman

I am gonna explain these through some examples below.
(Credits: This section was inspired by a brilliant post by Michael Dempsey. One of the most impactful blogposts I’ve read recently. I’ve quoted some lines verbatim.)
Unlimited Product Photography 📸
First impressions matter a lot. For D2C companies, great product photos are important however that process can be expensive. You’d have to hire editors, photographers or use some creative agency which does this work. But what if you could just click images from your phone and get these amazing photos!





How were these custom photos generated? 👇
We covered Dreambooth last week. This is a good real world use case for it.
The above is an example of a use case targeting new professional users. How? Remember the 3rd bullet point under new pro users section above? 👇
A lowered barrier of entry to a part of the industry that brings consumers or prosumers to professional level or removes the middleman
In this case, marketers/designers can create product photos themselves. No professional photography, editing needed!
Btw, this concept of new vs incumbent user isn’t exclusive to AI. Once you get it, you’ll start seeing it everywhere! eg: nocode website builder Webflow enabled marketers, designers to own the landing page. less to-and-fro with devs. new PRO users!
Reading tons of Research Papers? Save time using AI
What if while reading a paper you could just highlight long paras and get a concise explanation? Explainpaper made by Aman & Jade can do this!

Or say you want to save even more time! Elicit uses LLMs for automating research workflows. Here’s their latest feature.

Now if you refer back to the section on Pro users, I think this satisfies both categories:
Incumbent PRO: Better paper reading results in increase in efficiency, quality of work for Researchers who were already reading papers but they’ll see their existing “professional” workflows upended by AI ( Incumbent Pro Users).
New PRO: However, since these tools might be able to explain papers in simple words, they’ll also be useful to non-researcher demographics interested in learning about a topic from Research Papers directly. eg: health conscious folks wanting to read about the benefit of a certain health intervention or journalists who want to understand a topic better (instead of just talking to 5-10 experts, they could just synthesize answers from the Top 50-100 papers).
Using Stable Diffusion (SD) to generate synthetic data for STEM use cases by finetuning
Although we see SD as a way to generate these artistic images, it’s basically an image generator model. But there are many scientific applications where image datasets are needed. eg: Radiology!
Use of ML for Radiology has progressed a ton in the past 5 years but this is something out of the world! Finetuning Stable Diffusion to generate medical images. Great for increasing the diversity of your dataset! Which means better models.
I was gonna make a guess (whether this is for Incumbent or New Pro users) but I don’t really know a lot about medical data labelling, ML workflows 🤷♂️.


I think we’re gonna see Stable Diffusion finetuning being applied to more Computer Vision tasks soon. One I am particularly excited for: Geospatial Imagery (satellite data). Why? Story Time:
2 years ago, I was working on a geospatial project. It was something to do with roof detection in satellite images to determine best sites for solar panels (in Singapore). The satellite image dataset was small & blurry so I took up the task of converting low res into high res images. Now we were under certain time & resource contraints. To increase the dataset size, I gathered images of 3 other cities. But those cities looked very different from Singapore. I am leaving out a lot of detail but TLDR: I didn’t get satisfactory results.
If only I had Stable Diffusion back then…
A Twitter Discussion b/w Prompt Magicians
This is a snippet of a twitter discussion b/w some AI artists. Although making impressive stuff is quite easy now with all these tools, the Top 10% artists do a ton of tweaking to make their work stand apart. Art will always grow, AI models are just infinitely better multi-dimensional assistants/tools.
Generative art tools help make incumbent users (Artists) more productive but they also result in the birth of new artists!
If you want to improve your AI art, follow these discussions on twitter. I use a private Twitter List of Generative AI artists to follow these. I’ll be making that list public soon.
What’s New in Research 🧪
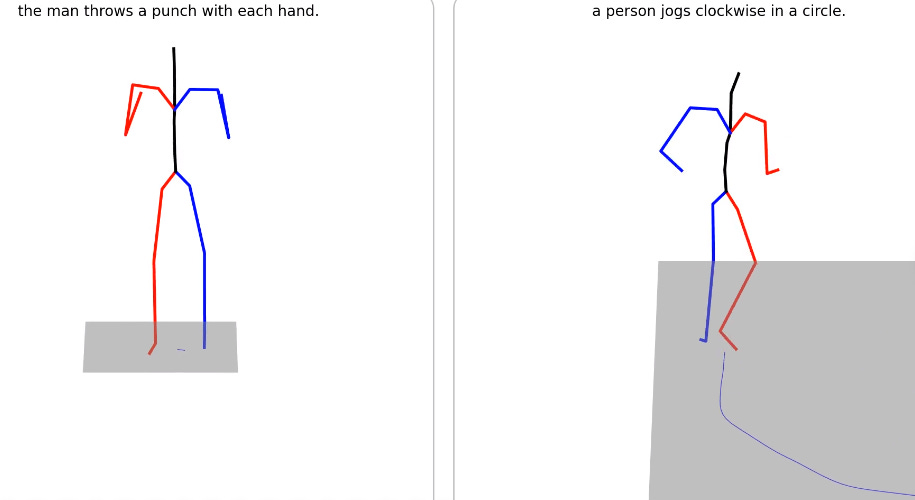
text2motion: MotionDiffuse, the first diffusion model-based text-driven motion generation framework. wondering what the output would be for “person sending out a newsletter 1 week late” 👻
text2light: generate panoramic scenes from text. more examples in the link.

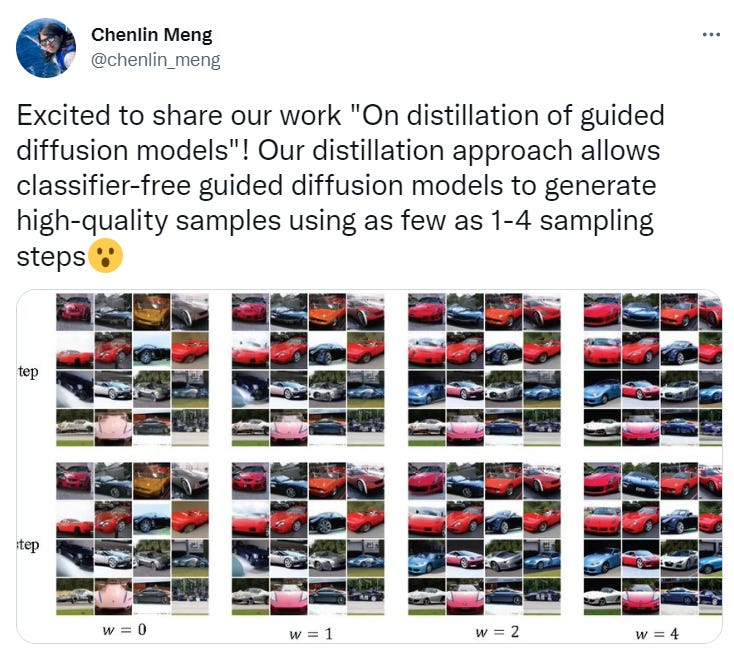
Generate images using fewer sampling steps: Right now, 28-50 steps are used for image creation, this new research can generate high quality samples in just 1-4 steps. Massive improvement! I think once this gets productized, it’ll unleash a ton of realtime applications. (link)
Progress in improving reasoning ability of LLMs 👇




🍨 Time for Dessart
Small Request: If you click on these tweets, do come back, there’s more 🤓! There’s also a poll 📊.




Make AI Music: what good is seeing all this art, if you don’t create some of your own, right? try this youtube tutorial. it’s pretty simple. If you’ve used Colab notebooks before, you can directly go to that (colab link).
Why try now? because this is in beta right now, so it’s free. (made by Mubert)
This performs fine for examples shown in the video but for advanced prompts you might not get good results. BUT text2music is just picking up, by Dec-Jan, this will be 5-10 times better.
AI-generated music clip for “car driving into sunset, synthwave”
🍬 Candies
👌 How do Diffusion Models work (explainer for both tech/non-tech folks)
👌 The Open Source movement is eating AI (thread)
👌 State of AI Report 2022: good summary of AI in 2022, not just Generative AI.
Dubverse.ai : generate English subtitles for videos in any language. built using OpenAI Whisper.
AI-generated podcast b/w Joe Rogan & Steve Jobs.
DreamSpace: a prompt diagramming tool, generate hundreds of images, manage prompt dependencies, try variations, find nearby concepts, and fine-tune params in real-time.
thought2text project by Samarth
awesome-diffusion-models: github repo of resources on diffusion models
Microsoft 🤝 DALL-E :
Create designs using DALLE : It’s basically a cheaper version of Canva🙃. Vertical Integration is the name of the game. btw, Canva has a Stable Diffusion integration too. I LOVE Canva. Fun Fact: CRW RIDE’s logo (temporary) and my twitter dp were also made/edited there.
Bing integration: Suppose you search for an image, don’t find one, then just create it! This was pretty obvious but I expected Google to integrate Imagen first, totally forgot that MSFT and OpenAI have a partnership. OpenAI is also looking to raise more $$$ from MSFT.

And now an update on CRW RIDE. scroll to the tweets section if you’re not interested.
The Main Course was text heavy today. The 1st issue was mostly news based. But as you saw above, this one had a central theme (Curiosity Phase, Pro vs New Users) so it took a bit of time. I was also busy with some other stuff last week.
I am going to prioritize actionable Insights»News.
There’s so much news out there that it’s impractical to keep up with all of it. Will be adding a new section to CRW RIDE (substack allows writers to make multiple newsletter sections) which’ll be optional.
Still debating b/w 2 ideas but I want to do a section dedicated to Builders, Artists so that would have more technical, prompt engineering related stuff while this one would be insight+news based. wdyt?
If you have any feedback / suggestions, feel free to reply to this mail, in the comment section or via Twitter (DMs open).
btw, if anyone is aware of some grant etc which supports work like CRW RIDE, lemme know 🙏.
👌 Tweets







Thanks for reading till the end! You’ve got top notch attention span💯🙌. If you liked what you read, do share this newsletter with your friends and on your socials :)